支持的芯片
芯片 |
RTL8721Dx |
RTL8720E |
RTL8726E |
RTL8730E |
|---|---|---|---|---|
支持情况 |
N |
N |
Y |
Y |
概述
AIVoice是一套由Realtek自主研发的离线AI解决方案,包含声学信号处理、唤醒、端点检测、识别等本地算法模块,可用于在Realtek SoC上搭建语音相关应用。
AIVoice可以作为纯离线方案单独使用,也可以结合语音识别、大语言模型等云端系统实现一个离在线混合的语音交互方案。
应用
智能语音系统广泛应用于多个领域,提升人机交互的效率和便捷性,其应用范围包括:
智能家居:如小爱音箱、天猫精灵等智能音箱设备,或是自带语音控制功能的家电产品,用户可以通过语音控制家中的灯光、温度和其他智能设备,提升居住的便利性和舒适度。
智能玩具:搭载智能语音系统的互动玩具(如AI故事机、语音教育机器人、陪伴机器人)正逐渐普及。这类玩具可通过语音与用户自然对话,回答十万个为什么、讲述定制化故事或进行双语教学。
车载系统:许多现代汽车配备了语音识别系统,允许驾驶员通过语音指令进行导航、拨打电话和播放音乐,确保驾驶安全并提升驾驶体验。
穿戴产品:如智能手表、智能耳机和健康监测设备等很多穿戴产品都配备了语音助手。用户可以通过语音指令查看和发送消息、控制音乐播放器、接听电话等,提升了用户体验和交互方式。
会议场景:语音识别技术可以实时转录会议内容,帮助与会者更好地记录和回顾讨论要点。
文件路径
芯片 |
操作系统 |
aivoice_lib_dir |
aivoice_example_dir |
|---|---|---|---|
RTL8730E |
Linux |
{LINUXSDK}/apps/aivoice |
{LINUXSDK}/apps/aivoice/example |
FreeRTOS |
{RTOSSDK}/component/aivoice |
{RTOSSDK}/component/example/aivoice |
|
RTL8726E |
FreeRTOS |
{DSPSDK}/lib/aivoice |
{DSPSDK}/example/aivoice |
模块
模块 |
功能 |
|---|---|
AFE(信号处理) |
增强语音信号、降噪 |
KWS(唤醒词检测) |
检测唤醒词以激活语音助手,例如“小爱同学”、“天猫精灵” |
VAD(语音端点检测) |
检测音频中的语音段或噪声段 |
ASR(语音识别) |
检测离线语音控制命令 |
流程
为了方便用户开发,部分算法流程已在AIVoice中实现:
- - Full Flow:
一个完整的离线流程,包括AFE,KWS和ASR。AFE和KWS始终开启,当KWS检测到唤醒词时,ASR开启并支持持续识别。超时后ASR退出。
- - AFE+KWS:
离线流程包括AFE和KWS,始终开启。
AFE(信号处理)
简介
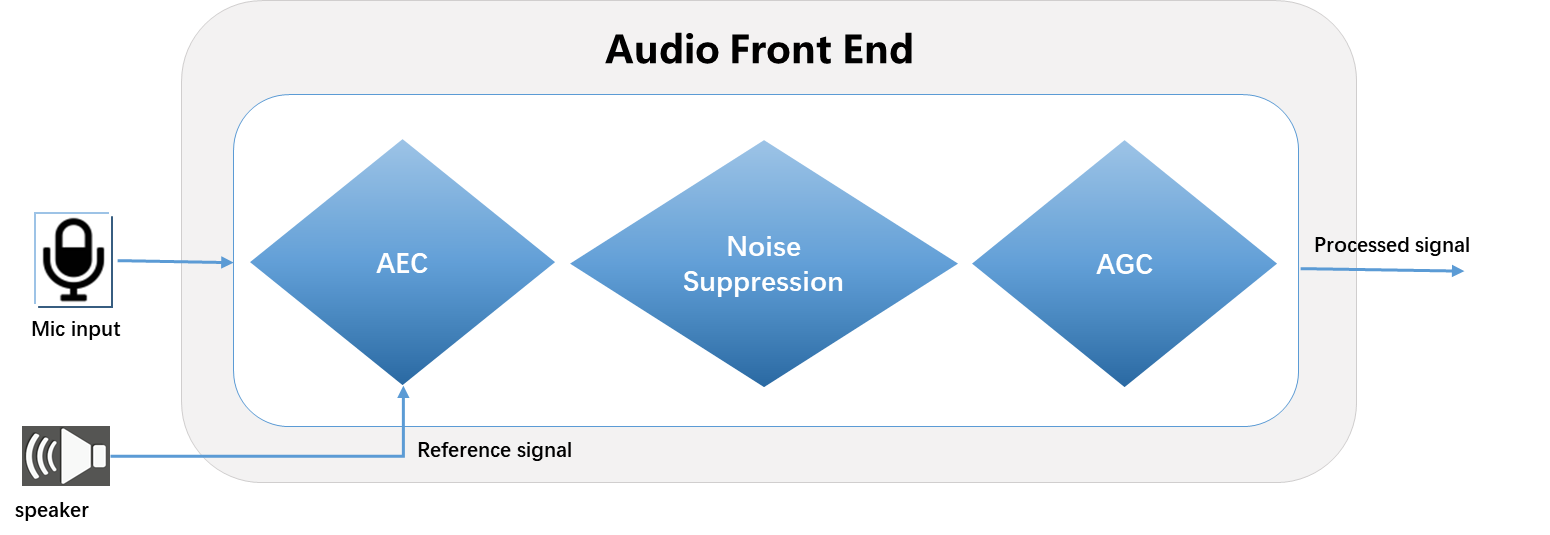
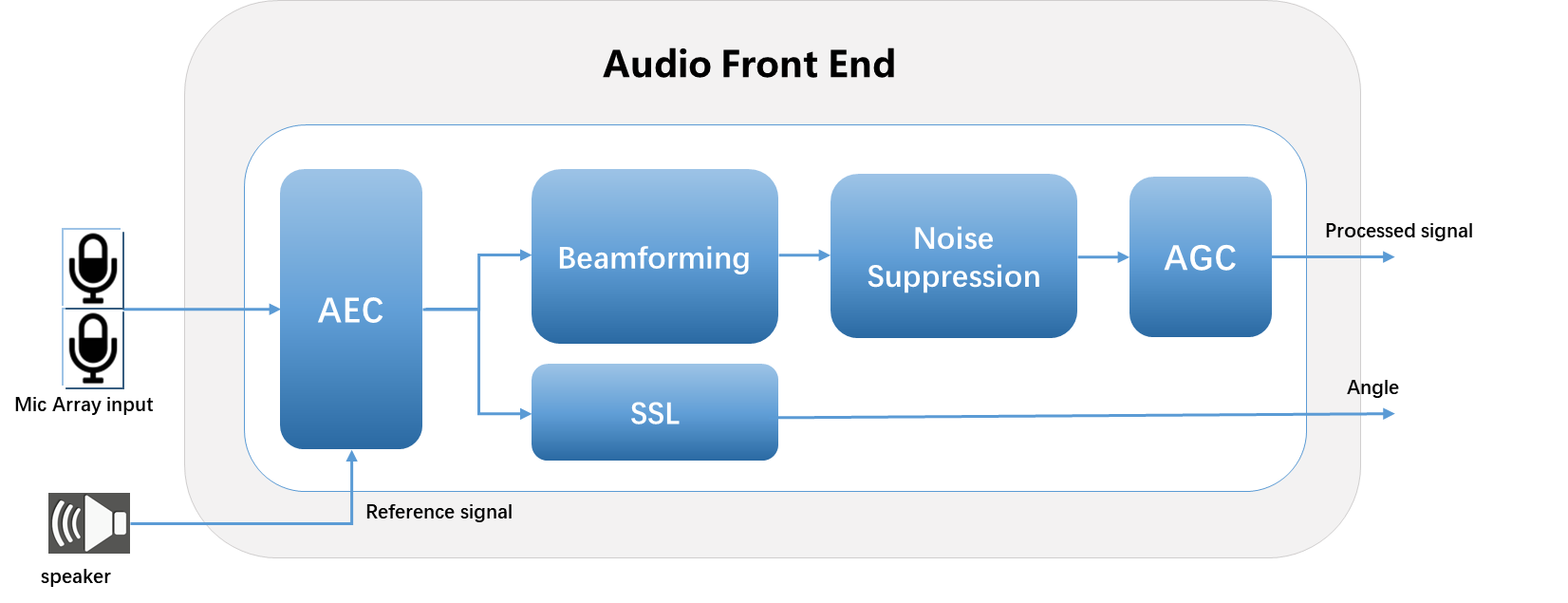
AFE是用于增强语音信号的音频信号处理模块。它可以提高语音识别系统的鲁棒性或改善通信系统的信号质量。
在AIVoice中,AFE算法包括以下子模块:
AEC(声学回声消除)
BF(波束成形)
NS(噪声抑制)
AGC(自动增益控制)
SSL(声源定位)
当前SDK中提供了以下四种麦克风阵型对应的算法库:
1mic
2mic_30mm
2mic_50mm
2mic_70mm
也可以通过定制服务提供其他麦克风阵列或性能优化。
算法框图
单麦克阵列
双麦克阵列
输入音频
单麦克阵列
输入音频的 格式 为 16 KHz、16 bit、双通道(其中 1 个通道为 mic 数据,另 1 个通道为参考信号)。 若不需要 AEC 功能,则输入为单通道 mic 数据。
输入音频的 帧长 固定为 256 个点。
数据排列示意图
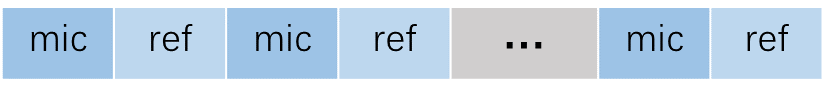
双麦克阵列
输入音频的 格式 为 16 KHz、16 bit、三通道(其中 2 个通道为 mic 数据,另 1 个通道为参考信号)。 若不需要 AEC 功能,则输入为两通道 mic 数据。
输入音频的 帧长 固定为 256 个点。
数据排列示意图
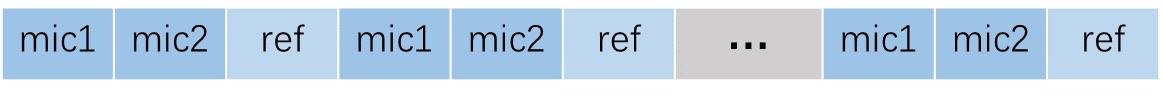
备注
当不需要 AEC 功能时, 相关参数应配置为:enable_aec = false, ref_num = 0 。
配置
配置参数定义
AFE配置包括麦克风阵列,模式,子模块开关等。
typedef struct afe_config{
// AFE common parameter
afe_mic_geometry_e mic_array; // microphone array. Make sure to choose the matched resource library
int ref_num; // reference channel number, must be 0 or 1. AEC will be disabled if ref_num=0.
int sample_rate; // sampling rate(Hz), must be 16000
int frame_size; // frame length(samples), must be 256
afe_mode_e afe_mode; // AFE mode, for ASR or voice communication. Only support AFE for ASR in current version.
bool enable_aec; // AEC(Acoustic Echo Cancellation) module switch
bool enable_ns; // NS(Noise Suppression) module switch
bool enable_agc; // AGC(Automation Gain Control) module switch
bool enable_ssl; // SSL(Sound Source Localization) module switch.
// AEC module parameter
afe_aec_mode_e aec_mode; // AEC mode, signal process or NN method. NN method is not supported in current version.
int aec_enable_threshold; // ref signal amplitude threshold for AEC, the value should be in [0, 100].
// larger value means the minimum echo to be cancelled will be larger.
bool enable_res; // AEC residual echo suppression module switch
afe_aec_filter_tap_e aec_cost; // higher cost means longer filter length and more echo reduction
afe_aec_res_aggressive_mode_e res_aggressive_mode; // higher mode means more residual echo suppression but more distortion
// NS module parameter
afe_ns_mode_e ns_mode; // NS mode, signal process or NN method. NN method is not supported in current version.
afe_ns_cost_mode_e ns_cost_mode; // low cost mode means 1channel NR and poorer noise reduction effect
afe_ns_aggressive_mode_e ns_aggressive_mode; // higher mode means more stationary noise suppression but more distortion
// AGC module parameter
int agc_fixed_gain; // AGC fixed gain(dB) applied on AFE output, the value should be in [0, 18].
bool enable_adaptive_agc; // adaptive AGC switch. Not supported in current version.
// SSL module parameter
float ssl_resolution; // SSL solution(degree)
int ssl_min_hz; // minimum frequency(Hz) of SSL module.
int ssl_max_hz; // maximum frequency(Hz) of SSL module.
} afe_config_t;
如果需要修改麦克风阵列,请确保配置和afe资源库做对应的修改。
详情请参考 ${aivoice_lib_dir}/include/aivoice_afe_config.h。
注意
请确保 mic_array 、ref_num 两个参数与 AFE 输入音频匹配。
模块开关配置
AEC(回声消除)
模块说明: 用于消除麦克风拾取的设备自身播放的声音即回声。
开启条件: 当设备带喇叭,有带回声场景时,应开启AEC模块。
模块开启前后频谱对比
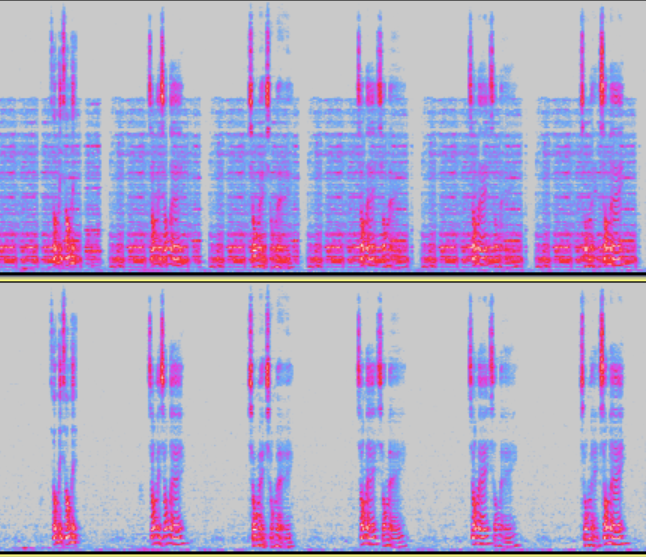
RES(残留回声抑制)
模块说明: 为AEC模块中的非线性处理子模块,用于进一步抑制回声残留。 当该模块开启时回声抑制更强,但同时语音损伤也会增加。
开启条件: 当喇叭播放时非线性较强,回声残留较高时,可以开启RES模块。 当AEC模块关闭时,该模块无法单独开启。
模块开启前后频谱对比
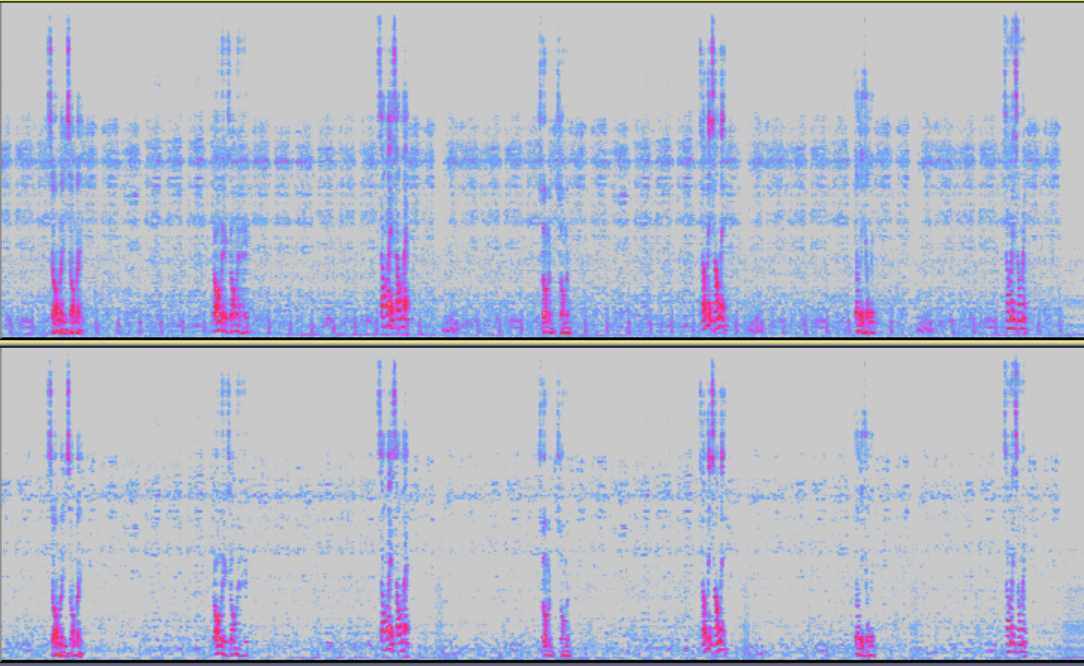
NS(噪声抑制)
模块说明: 用于抑制环境噪声,主要是对稳态噪声,具有很好的抑制效果。
开启条件: 当使用场景环境噪声较高或设备本身会发出较大稳态噪声,推荐开启NS模块。
模块开启前后频谱对比
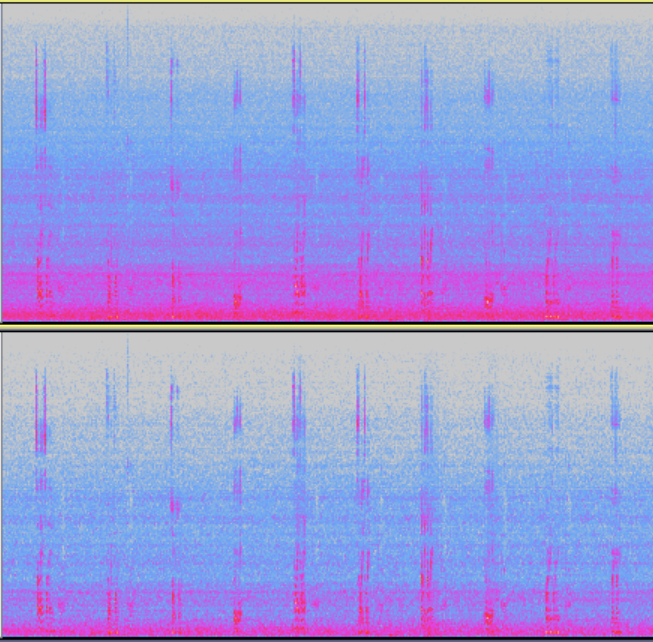
AGC (自动增益控制)
模块说明: 用于调整输出音频的幅值。 调整agc_fixed_gain参数时,应保证在语音音量最大情况下,处理后的信号不截幅。
开启条件: 当输出信号幅度偏低明显影响识别或唤醒效果时,可以开启AGC模块,施加适当的增益。
SSL (声源定位)
模块说明: 用于计算目标说话人的方向。 仅支持双麦克阵列,输出角度范围为 0° ~ 180°。
开启条件: 当需要获取说话人方向时,可以开启SSL模块。
硬件设计要求
麦克风单体性能推荐
麦克风建议优选全向性硅麦,一致性更好。
灵敏度(sensitivity):模拟硅麦 ≥-38dBV,数字硅麦 ≥-26dBFS,±1.5dB;
信噪比(SNR) :≥60dB
总体谐波失真(THD) :≤ 1%(1kHz)
声学过载点(AOP) :≥120dB SPL
喇叭单体性能推荐
谐波失真(THD):额定功率下 100~200Hz THD≤5%,200~8kHz THD≤3%
麦克阵列设计建议
2 个麦克风之间间距建议保持 3.0~7.0 cm,优选5cm。
所有麦克风收音口位于同一直线,该直线平行于水平面。
麦克风朝向可以在朝上与朝前(朝向说话人)之间任意角度。
推荐同一个阵列内的麦克应使用同一厂家的同一型号,不建议混用。
麦克阵列中各麦克的结构设计,推荐采用相同的设计,以保证结构设计的一致性。
整机拾音性能要求
一致性
频响一致性:自由场频谱(100~7kHz)响应波动: < 3dB 。
相位一致性:麦克风之间的相位差(1kHz): < 10°。
气密性
外部喇叭播放,堵上麦克风与不堵上麦克风收音的音量差值(100~8 kHz): > 15dB。
频谱无异常
不应有异常的电噪声。
不应有丢音。
频谱衰减
7.5kHz频率以下不应有明显的衰减。
频率混叠
播放扫频信号(0~20 kHz),16kHz收音信号没有明显频率混叠。
整机播放回采性能要求
回采接入方式
仅支持硬回采,不支持软回采。
回采接入位置
回采位置推荐尽量靠近喇叭侧,需接在EQ之后,以规避音效导致的非线性。
回采增益
设备喇叭最大音量播放时,回采信号不应截幅,建议参考峰值 -3~-6 dB。
时延
不要有时延。
总谐波失真
设备喇叭最大音量播放时,100Hz,THD≤10%; 200~500Hz,THD≤6%; 500~8kHz,THD≤3%。
气密性
设备喇叭播放,堵上麦克风与不堵上麦克风收音的音量差值(100~8 kHz): > 15dB。
KWS(唤醒词检测)
简介
KWS是用于检测音频中特定唤醒词的模块。它通常是语音交互的第一步,设备检测到唤醒词后,会进入等待语音指令状态。
AIVoice支持两种KWS算法方案:
方案 |
训练数据 |
可选唤醒词 |
方案特点 |
|---|---|---|---|
固定唤醒词 |
特定唤醒词 |
训练数据所用唤醒词 |
性能更好;模型更小 |
自定义唤醒词 |
通用数据 |
与训练数据相同语种的任意自定义唤醒词 |
更灵活 |
当前SDK中提供了一个“小强小强”或“你好小强”的中文固定唤醒词模型和一个中文自定义唤醒模型。也可以通过定制服务提供其他唤醒词或性能优化。
配置
KWS可配参数:
- - keywords:
唤醒关键字, 可选的关键字取决于KWS模型。如果KWS模型是固定唤醒词方案,则只能从训练过的单词中选择。对于自定义唤醒词方案,可以使用该语言建模单元的任意组合来定制关键字(例如中文拼音)。示例:”xiao-qiang-xiao-qiang”。
- - thresholds:
唤醒阈值,范围[0, 1]。值越高,误唤醒越少,但更难唤醒。如果要使用灵敏度,该值需要设为0。
- - sensitivity:
提供预先调好阈值的三档灵敏度,灵敏度越高,更容易唤醒,但误唤醒也越多。 灵敏度仅在阈值设置为0时有效。
详情请参考 ${aivoice_lib_dir}/include/aivoice_kws_config.h。
KWS模式
有单路或多路两种KWS模式可供不同使用场景选择。与单路相比,多路模式可以提升KWS和ASR的准确率,但同时计算资源和内存使用也会上升。
KWS模式 |
函数 |
特点 |
|---|---|---|
单路模式 |
void rtk_aivoice_set_single_kws_mode(void) |
更少的计算量和内存占用 |
多路模式 |
void rtk_aivoice_set_multi_kws_mode(void) |
更高的唤醒率和识别率 |
注意
在这些流程中创建实例之前必须设置KWS模式:
aivoice_iface_full_flow_v1
aivoice_iface_afe_kws_v1
VAD(语音端点检测)
简介
VAD是用于检测音频中有无语音信号的模块。
AIVoice提供了一个基于神经网络的VAD算法,可以用于语音增强、识别等语音系统中。
配置
VAD可配参数:
- - sensitivity:
提供预先调好阈值的三档灵敏度,灵敏度越高,越容易检测到语音,但误报也越多。
- - left_margin:
添加到语音段开头的时间边距,使起始点早于原始的预测点。该值仅影响VAD输出的offset_ms,不会影响状态1的事件触发时间。
- - right_margin:
添加到语音段结尾的时间边距,使结尾点晚于原始的预测点。该值同时影响VAD输出的offset_ms和状态0的事件触发时间。
详情请参考 ${aivoice_lib_dir}/include/aivoice_vad_config.h。
备注
left_margin参数仅影响vad返回的offset_ms数值, 无法影响vad状态的改变时间. 如果需要保留left_margin区间内的音频,请在外部通过音频缓存实现。
ASR(语音识别)
简介
ASR是用于把语音信号识别为文本的模块。
AIVoice提供了中文离线语音命令词检测的ASR算法。
当前SDK中提供了一套包含“打开空调” “关闭空调”等空调相关的40条命令词的识别算法,也可以通过定制服务更换命令词、性能优化等。
配置
ASR可配参数:
- - sensitivity:
提供预先调好阈值的三档灵敏度,灵敏度越高,更容易识别到命令词,但误触发也越多。
详情请参考 ${aivoice_lib_dir}/include/aivoice_asr_config.h。
接口
流程和模块接口
接口 |
流程/模块 |
|---|---|
aivoice_iface_full_flow_v1 |
AFE+KWS+ASR |
aivoice_iface_afe_kws_v1 |
AFE+KWS |
aivoice_iface_afe_v1 |
AFE |
aivoice_iface_vad_v1 |
VAD |
aivoice_iface_kws_v1 |
KWS |
aivoice_iface_asr_v1 |
ASR |
所有接口均支持以下函数:
create()
destroy()
reset()
feed()
详情请参考 ${aivoice_lib_dir}/include/aivoice_interface.h。
事件及回调信息
aivoice输出事件 |
事件触发时间 |
回调信息 |
|---|---|---|
AIVOICE_EVOUT_VAD |
当VAD检测到语音段开始或结束 |
包含VAD状态,偏移的结构体 |
AIVOICE_EVOUT_WAKEUP |
当KWS检测到唤醒词 |
包含id,唤醒词,唤醒得分的json字符串。示例: {“id”:2,”keyword”:”ni-hao-xiao-qiang”,”score”:0.9} |
AIVOICE_EVOUT_ASR_RESULT |
当ASR检测到命令词 |
包含fst类型,命令词,id的json字符串。 示例: {“type”:0,”commands”:[{“rec”:”打开空调”,”id”:14}]} |
AIVOICE_EVOUT_AFE |
AFE收到输入的每一帧 |
包含AFE输出数据,通道数等的结构体 |
AIVOICE_EVOUT_ASR_REC_TIMEOUT |
在给定的超时期限内未检测到命令字时 |
NULL |
AFE事件定义
struct aivoice_evout_afe {
int ch_num; /* channel number of output audio signal, default: 1 */
short* data; /* enhanced audio signal samples */
char* out_others_json; /* reserved for other output data, like flags, key: value */
};
VAD事件定义
struct aivoice_evout_vad {
int status; /* 0: vad is changed from speech to silence,
indicating the end point of a speech segment
1: vad is changed from silence to speech,
indicating the start point of a speech segment */
unsigned int offset_ms; /* time offset relative to reset point. */
};
通用配置
AIVoice可配参数:
- - no_cmd_timeout:
如果在此持续时间内未检测到命令字,则ASR退出。 仅在full flow中使用。
- - memory_alloc_mode:
默认使用SDK默认堆。SRAM模式使用SDK默认堆,同时还从SRAM分配空间用于内存关键数据。 SRAM模式目前仅适用于RTL8713EC和RTL8726EA DSP。
详情请参考 ${aivoice_lib_dir}/include/aivoice_sdk_config.h。
示例
AIVoice Full Flow离线示例
该例子通过一条提前录制的三通道音频演示如何使用AIVoice的全流程,在开发板启动后仅运行一次。 未整合录音、播放等音频功能。
AIVoice使用步骤
选择需要的aivoice流程或模块。如果使用full_flow或afe_kws流程,需要指定KWS模式为单路或多路模式。
/* step 1: * Select the aivoice flow you want to use. * Refer to the end of aivoice_interface.h to see which flows are supported. */ const struct rtk_aivoice_iface *aivoice = &aivoice_iface_full_flow_v1; rtk_aivoice_set_multi_kws_mode();
准备配置参数。
/* step 2: * Modify the default configure if needed. * You can modify 0 or more configures of afe/vad/kws/... */ struct aivoice_config config; memset(&config, 0, sizeof(config)); /* * here we use afe_res_2mic50mm for example. * you can change these configuratons according the afe resource you used. * refer to aivoce_afe_config.h for details; * * afe_config.mic_array MUST match the afe resource you linked. */ struct afe_config afe_param = AFE_CONFIG_ASR_DEFAULT(); afe_param.mic_array = AFE_LINEAR_2MIC_50MM; // change this according to the linked afe resource. config.afe = &afe_param; /* * ONLY turn on these settings when you are sure about what you are doing. * it is recommend to use the default configure, * if you do not know the meaning of these configure parameters. */ struct vad_config vad_param = VAD_CONFIG_DEFAULT(); vad_param.left_margin = 300; // you can change the configure if needed config.vad = &vad_param; // can be NULL struct kws_config kws_param = KWS_CONFIG_DEFAULT(); config.kws = &kws_param; // can be NULL struct asr_config asr_param = ASR_CONFIG_DEFAULT(); config.asr = &asr_param; // can be NULL struct aivoice_sdk_config aivoice_param = AIVOICE_SDK_CONFIG_DEFAULT(); aivoice_param.no_cmd_timeout = 10; config.common = &aivoice_param; // can be NULL
使用
create()和指定配置来创建并初始化aivoice实例。/* step 3: * Create the aivoice instance. */ void *handle = aivoice->create(&config); if (!handle) { return; }
注册回调函数。
/* step 4: * Register a callback function. * You may only receive some of the aivoice_out_event_type in this example, * depending on the flow you use. * */ rtk_aivoice_register_callback(handle, aivoice_callback_process, NULL);
回调函数可以按实际使用需求进行修改:
static int aivoice_callback_process(void *userdata, enum aivoice_out_event_type event_type, const void *msg, int len) { (void)userdata; struct aivoice_evout_vad *vad_out; struct aivoice_evout_afe *afe_out; switch (event_type) { case AIVOICE_EVOUT_VAD: vad_out = (struct aivoice_evout_vad *)msg; printf("[user] vad. status = %d, offset = %d\n", vad_out->status, vad_out->offset_ms); break; case AIVOICE_EVOUT_WAKEUP: printf("[user] wakeup. %.*s\n", len, (char *)msg); break; case AIVOICE_EVOUT_ASR_RESULT: printf("[user] asr. %.*s\n", len, (char *)msg); break; case AIVOICE_EVOUT_ASR_REC_TIMEOUT: printf("[user] asr timeout\n"); break; case AIVOICE_EVOUT_AFE: afe_out = (struct aivoice_evout_afe *)msg; // afe will output audio each frame. // in this example, we only print it once to make log clear static int afe_out_printed = false; if (!afe_out_printed) { afe_out_printed = true; printf("[user] afe output %d channels raw audio, others: %s\n", afe_out->ch_num, afe_out->out_others_json ? afe_out->out_others_json : "null"); } // process afe output raw audio as needed break; default: break; } return 0; }
使用
feed()给aivoice输入音频数据。/* when run on chips, we get online audio stream, * here we use a fix audio. * */ const char *audio = (const char *)get_test_wav(); int len = get_test_wav_len(); int audio_offset = 44; int mics_num = 2; int afe_frame_bytes = (mics_num + afe_param.ref_num) * afe_param.frame_size * sizeof(short); while (audio_offset <= len - afe_frame_bytes) { /* step 5: * Feed the audio to the aivoice instance. * */ aivoice->feed(handle, (char *)audio + audio_offset, afe_frame_bytes); audio_offset += afe_frame_bytes; }
(可选) 如果需要重置状态, 使用
reset()。如果不再需要aivoice,使用
destroy()销毁实例。/* step 6: * Destroy the aivoice instance */ aivoice->destroy(handle);
详情请参考 ${aivoice_example_dir}/full_flow_offline 。
编译示例
编译DSP的Tensorflow Lite Micro库, 请参考 编译Tensorflow Lite Micro库。
也可使用{DSPSDK}/lib/aivoice/prebuilts目录下预编译好的Tensorflow Lite Micro库。
在Xtensa Xplorer中导入
{DSPSDK}/example/aivoice/full_flow_offline源。进行软件相关配置,按需修改链接的库如AFE资源、KWS资源等。
添加包含路径 (-I)
${workspace_loc}/../lib/aivoice/include
添加库搜索路径 (-L)
${workspace_loc}/../lib/aivoice/prebuilts/$(TARGET_CONFIG) ${workspace_loc}/../lib/xa_nnlib/v1.8.1/bin/$(TARGET_CONFIG)/Release ${workspace_loc}/../lib/lib_hifi5/project/hifi5_library/bin/$(TARGET_CONFIG)/Release ${workspace_loc}/../lib/tflite_micro/project/bin/$(TARGET_CONFIG)/Release
添加库 (-l)
-laivoice -lafe_kernel -lafe_res_2mic50mm -lkernel -lvad -lkws -lasr -lfst -lcJSON -ltomlc99 -ltflite_micro -lxa_nnlib -lhifi5_dsp
编译固件,请参考 dsp_build 中的步骤。
FreeRTOS
切换到gcc project目录
cd {SDK}/amebasmart_gcc_project ./menuconfig.py
导航至以下菜单路径开启Tensorflow Lite Micro库和AIVoice
--------MENUCONFIG FOR General--------- CONFIG TrustZone ---> ... CONFIG APPLICATION ---> GUI Config ---> ... AI Config ---> [*] Enable TFLITE MICRO [*] Enable AIVoice
根据硬件选择相应的AFE资源,默认afe_res_2mic50mm
AI Config ---> [*] Enable TFLITE MICRO [*] Enable AIVoice Select AFE Resource ( ) afe_res_1mic ( ) afe_res_2mic30mm (X) afe_res_2mic50mm ( ) afe_res_2mic70mm
选择KWS资源,默认固定唤醒词“小强小强”、“你好小强”
AI Config ---> [*] Enable TFLITE MICRO [*] Enable AIVoice Select AFE Resource Select KWS Resource (X) kws_res_xqxq ( ) kws_res_custom
编译固件
./build.py -a full_flow_offline
Linux
(可选) 如果需要更换AFE资源或KWS资源,修改yocto recipe
{LINUXSDK}/yocto/meta-realtek/meta-sdk/recipes-rtk/aivoice/rtk-aivoice-algo_1.2.bb.里的库。通过bitbake编译aivoice可执行文件:
bitbake rtk-aivoice-algo
术语
- AEC
AEC(Acoustic Echo Cancellation),声学回声消除,或回声消除,是指消除输入信号中的回声信号。回声信号是指麦克风采集到的设备自身扬声器播放的音频。
- AFE
AFE(Audio Front End),音频前端,或信号处理,是指用于原始音频信号预处理的一些模块的组合。通常在进行语音交互前执行以增强信号质量,包含多种语音增强算法。
- AGC
AGC(Automatic Gain Control),自动增益控制,用于动态调节信号的增益,自动调整信号幅值,以保持最佳信号强度。
- ASR
ASR(Automatic Speech Recognition),语音识别,是指把音频中的语音识别为文本。它可用于搭建语音用户界面,实现人类与人工智能设备的语音交互。
- BF
BF(BeamForming),波束形成,是指一种为麦克风阵列设计的空间滤波器,用于增强来自特定方向的信号同时衰减其他方向的信号。
- KWS
KWS(Keyword Spotting),关键词检测,或唤醒词检测、语音唤醒,是指从音频中识别特定的唤醒词。通常是语音交互的第一步,设备检测到唤醒词后,会进入等待语音指令状态。
- NN
NN(Neural Network),神经网络,是一种用于人工智能各类任务的机器学习模型。神经网络依靠训练数据学习并提升准确性。
- NS
NS(Noise Suppression),噪声抑制,或降噪,是指抑制信号中的环境噪声以增强语音信号, 尤其是稳态噪声。
- RES
RES(Residual Echo Suppression),残余回声抑制,是指抑制AEC处理后的残余回声信号。是AEC的后置滤波器。
- SSL
SSL(Sound Source Localization),声源定位,是指利用麦克风阵列估计声源的空间方位。
- TTS
TTS(Text-To-Speech),语音合成,是一种将文本转换为语音的技术。它可用于各种需要将文本转换为人声的语音应用中。
- VAD
VAD (Voice Activity Detection),语音活性检测,或语音端点检测,是指从音频中检测有无语音信号。它被广泛用于语音增强、语音识别等系统中,也可用于去除音频会话中的非语音片段以减少计算、带宽等。