Supported SoCs
SoC |
RTL8721Dx |
RTL8720E |
RTL8726E |
RTL8730E |
|---|---|---|---|---|
Supported |
N |
N |
Y |
Y |
Overview
AIVoice is an offline AI solution developped by Realtek, including local algorithm modules like Audio Front End (Signal Processing), Keyword Spotting, Voice Activity Detection, Speech Recognition etc. It can be used to build voice related applications on Realtek Ameba SoCs.
AIVoice can be used as a purely offline solution on its own, or it can be combined with cloud systems such as voice recognition, LLMs to create a hybrid online and offline voice interaction solution.
Applications
The smart voice system is widely applied in various fields and products, enhancing the efficiency and convenience of human-computer interaction. The applications including:
Smart Home: Smart speakers like Amazon Echo and Google Nest, or home appliances with built-in voice control features, allow users to control home lighting, temperature, and other smart devices through voice commands, enhancing convenience and comfort in living.
Smart Toys: Intelligent voice systems are being integrated into interactive toys (like AI story machines and voice-enabled educational robots, companion robots). These toys can engage in natural conversations with users, answering endless questions, telling personalized stories, or providing bilingual education.
In-Car Systems: Many modern vehicles are equipped with voice recognition systems that enable drivers to navigate, make calls, and play music using voice commands, ensuring driving safety and also making the driving experience more enjoyable.
Wearable Products: Many products include smartwatches, smart headphones, and health monitoring devices come equipped with voice assistants. User can use voice control to check and send messages, control music player, answer calls etc, enhancing user experience and interaction methods.
Meeting Scenarios: Voice recognition technology can transcribe meeting content in real-time, helping participants better record and review discussion points.
File Path
Chip |
OS |
aivoice_lib_dir |
aivoice_example_dir |
|---|---|---|---|
RTL8730E |
Linux |
{LINUXSDK}/apps/aivoice |
{LINUXSDK}/apps/aivoice/example |
FreeRTOS |
{RTOSSDK}/component/aivoice |
{RTOSSDK}/component/example/aivoice |
|
RTL8726E |
FreeRTOS |
{DSPSDK}/lib/aivoice |
{DSPSDK}/example/aivoice |
Modules
Modules |
Functions |
|---|---|
AFE (Audio Front End) |
Enhancing speech signals and reducing noise |
KWS (Keyword Spotting) |
Detecting specific wakeup words to trigger voice assistants, such as “Hey siri”, “Alexa” |
VAD (Voice Activity Detection) |
Detecting speech segments or noise segments |
ASR (Automatic Speech Recognition) |
Detecting offline voice control commands |
Flows
Some algorithm flows have been implemented to facilitate user development.
- - Full Flow:
An offline full flow including AFE, KWS and ASR. AFE and KWS are always-on, ASR turns on and supports continuous recognition when KWS detects the keyword. ASR exits after timeout.
- - AFE+KWS:
Offline flow including AFE and KWS, always-on.
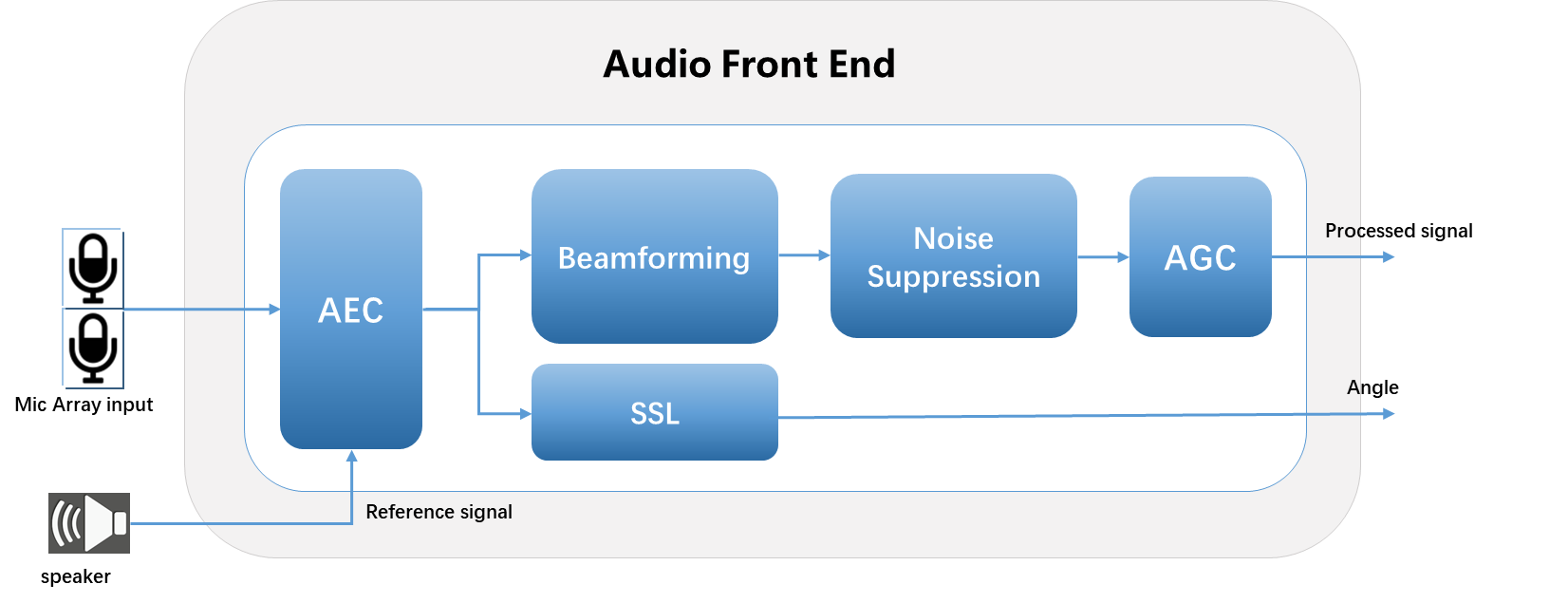
AFE (Audio Front End)
Introduction
AFE is audio signal processing module for enhancing speech signals. It can improve robustness of speech recognition system or improve signal quality of communication system.
In AIVoice, AFE includes submodules:
AEC (Acoustic Echo Cancellation)
BF (Beamforming)
NS (Noise Suppression)
AGC (Automatic Gain Control)
SSL (Sound Source Localization)
Currently SDK provides libraries for four microphone arrays:
1mic
2mic_30mm
2mic_50mm
2mic_70mm
Other microphone arrays or performance optimizations can be provided through customized services.
Algorithm Flow
Single Mic
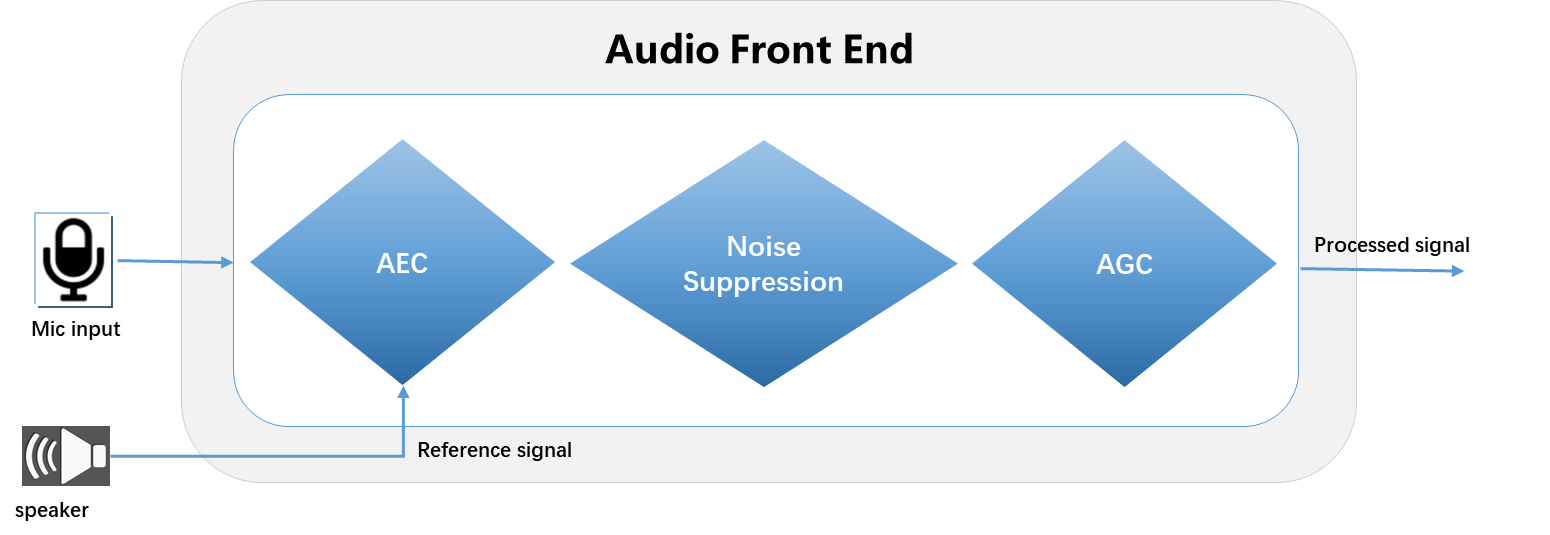
Dual Mic
Input Audio Data
Single Mic
Input audio data format: 16 kHz, 16 bit, two channels (one is mic data, another is ref data). If AEC is not required, the input is single-channel of mic data.
The frame length of input audio data is fixed at 256 samples.
The input data is arranged as follows:
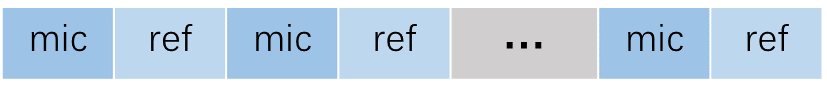
Dual Mic
Input audio data format: 16 kHz, 16 bit, there channels (two are mic data, another is ref data). If AEC is not required, the input is two-channels of mic data.
The frame length of input audio data is fixed at 256 samples.
The input data is arranged as follows:
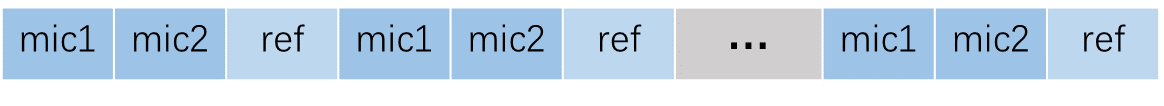
Note
If AEC is not required, Set related parameters as follows: enable_aec = false, ref_num = 0 。
Configurations
Definition of Configuration Parameters
AFE configuration includes microphone array, working mode, submodule switches, etc.
typedef struct afe_config{
// AFE common parameter
afe_mic_geometry_e mic_array; // microphone array. Make sure to choose the matched resource library
int ref_num; // reference channel number, must be 0 or 1. AEC will be disabled if ref_num=0.
int sample_rate; // sampling rate(Hz), must be 16000
int frame_size; // frame length(samples), must be 256
afe_mode_e afe_mode; // AFE mode, for ASR or voice communication. Only support AFE for ASR in current version.
bool enable_aec; // AEC(Acoustic Echo Cancellation) module switch
bool enable_ns; // NS(Noise Suppression) module switch
bool enable_agc; // AGC(Automation Gain Control) module switch
bool enable_ssl; // SSL(Sound Source Localization) module switch.
// AEC module parameter
afe_aec_mode_e aec_mode; // AEC mode, signal process or NN method. NN method is not supported in current version.
int aec_enable_threshold; // ref signal amplitude threshold for AEC, the value should be in [0, 100].
// larger value means the minimum echo to be cancelled will be larger.
bool enable_res; // AEC residual echo suppression module switch
afe_aec_filter_tap_e aec_cost; // higher cost means longer filter length and more echo reduction
afe_aec_res_aggressive_mode_e res_aggressive_mode; // higher mode means more residual echo suppression but more distortion
// NS module parameter
afe_ns_mode_e ns_mode; // NS mode, signal process or NN method. NN method is not supported in current version.
afe_ns_cost_mode_e ns_cost_mode; // low cost mode means 1channel NR and poorer noise reduction effect
afe_ns_aggressive_mode_e ns_aggressive_mode; // higher mode means more stationary noise suppression but more distortion
// AGC module parameter
int agc_fixed_gain; // AGC fixed gain(dB) applied on AFE output, the value should be in [0, 18].
bool enable_adaptive_agc; // adaptive AGC switch. Not supported in current version.
// SSL module parameter
float ssl_resolution; // SSL solution(degree)
int ssl_min_hz; // minimum frequency(Hz) of SSL module.
int ssl_max_hz; // maximum frequency(Hz) of SSL module.
} afe_config_t;
If you need to change mic_array, both configuration and afe resource library should change accordingly.
Please refer to ${aivoice_lib_dir}/include/aivoice_afe_config.h for details.
Attention
Please make sure the mic_array and ref_num in configuration match AFE input audio.
Module Switch Configuration
AEC(Acoustic Echo Cancellation)
Module Description: To cancel the sound played by the device itself picked up by the microphone known as echo.
Enable Condition: When the device is equipped with speaker and there are echo scenes, the AEC module should be enabled.
Spectrum when AEC module is off and on
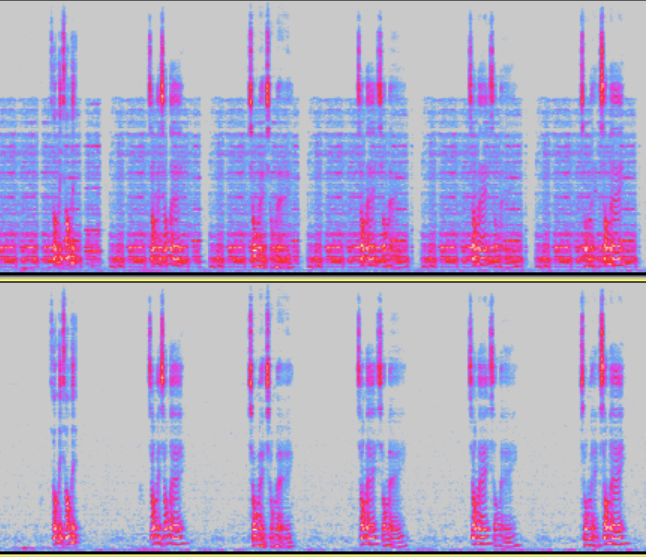
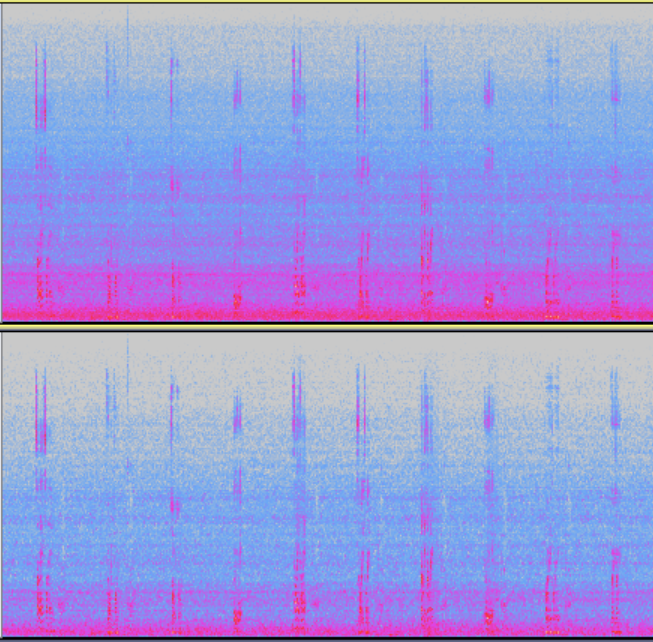
RES(Residual Echo Suppression)
Module Description: Nonlinear processing submodule of AEC for further suppressing the residual echo. When this module is enabled, echo suppression is enhanced, but speech distortion also increases.
Enable Condition: When the speaker plays with strong nonlinearity and high echo residue, the RES module can be enabled. RES module cannot be enabled individually when AEC is disabled.
Spectrum when RES module is off and on
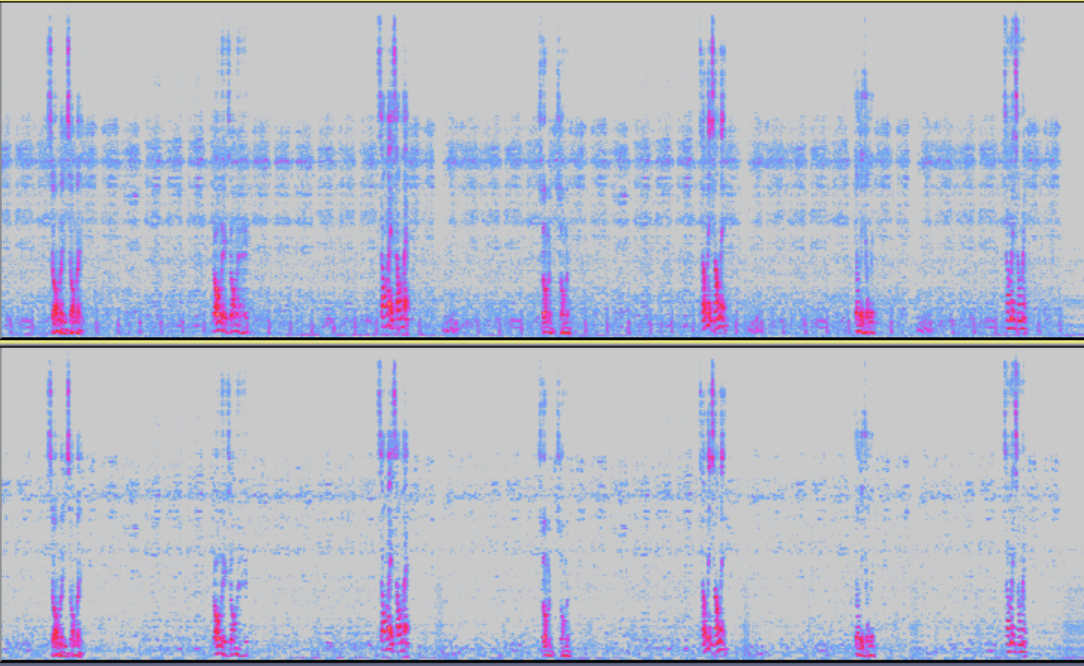
NS(Noise Suppression)
Module Description: To suppress ambient noise, especially for stationary noise.
Enable Condition: When the environment noise is high or the device generates large stationary noise, the NS module is advised to enabled.
Spectrum when NS module is off and on
AGC (Automatic Gain Control)
Module Description: To adjust the amplitude of the output audio. When adjusting the AGC_fixed_gain parameter, ensure that the processed signal is not clipped under maximum speech volume conditions.
Enable Condition: When the output signal amplitude obviously affects the KWS or ASR effect, the AGC module can be enabled to apply the appropriate gain.
SSL (Sound Source Localization)
Module Description: To calculate the direction of the speaker. Only dual-microphone arrays are supported, and the output Angle ranges from 0° to 180°.
Enable Condition: Enable SSL module when the direction information of speaker is needed.
Hardware Design Requirements
Microphone performance requirements
Omnidirectional MEMS microphone is recommended, it has better consistency.
sensitivity: analog microphones ≥-38dBV, digital microphones ≥-26dBFS, ±1.5dB;
Signal-to-noise ratio (SNR): ≥60dB
Overall-harmonic-distortion(THD) :≤ 1%(1kHz)
Acoustic overload point(AOP) :≥120dB SPL
Speaker performance requirements
Harmonic distortion (THD) : under rated power 100~200Hz THD≤5% , 200~8kHz THD≤3%
Microphone Array Design Recommend
the distance between two microphones should be 3.0~7.0 cm, preferably 5cm.
All microphone pickup holes are located in the same straight line, which is parallel to the horizontal plane.
The microphone orientation can be at any Angle between up and forward (towards the speaker).
Use the same microphone models from the same manufacturer for the array. It’s not recommended to use different microphone models in the same array.
It is recommended to use the same structural design for all the microphones in the same array to ensure consistency.
Receive Path Performance Requirements
Consistency
Frequency response consistency: free field spectrum (100~7kHz) response fluctuation: < 3dB.
Phase consistency: phase difference between microphones (1kHz) : < 10°.
Leakproofness
External speaker playback, the overall volume attenuation (100~8kHz) between blocked microphone pickup hole and unblocked microphone pickup hole : > 15dB.
No Abnormality in the Spectrum
There should be no abnormal electrical noise.
There should be no data loss.
Spectrum Attenuation
There should be no significant attenuation below 7.5kHz.
Frequency Aliasing
Play the sweep signal (0~20 kHz), and the recording signal has no significant frequency aliasing.
Echo Path Performance Requirements
Loopback mode for echo reference
Only supports hardware loopback for echo reference.
Echo reference signal position
It is recommended that the echo reference signal be as close to the speaker side as possible, and should be after EQ to avoid nonlinear caused by sound effects.
Reference signal gain
When the speaker playback at the maximum volume, the echo reference signal should not have clipping, the Recommended signal peak value is -3 to -6 dB.
Latency
Don’t have latency.
Total harmonic distortion
When the speaker playback at the maximum volume: 100Hz, THD≤10%; 200~500Hz, THD≤6%; 500~8kHz, THD≤3%.
Leakproofness
Device speaker playback, the overall volume attenuation (100~8kHz) between blocked microphone pickup hole and unblocked microphone pickup hole : > 15dB.
KWS (Keyword Spotting)
Introduction
KWS is the module to detect specific wakeup words from audio. It is usually the first step in a voice interaction system. The device will enter the state of waiting voice commands after detecting the keyword.
In AIVoice, two solutions of KWS are available:
Solution |
Training Data |
Available Keywords |
Feature |
Fixed Keyword |
specific keywords |
keywords same as training data |
better performance; smaller model |
Customized Keyword |
common data |
customized keyword of the same language as training data |
more flexible |
Currently SDK provides a fixed keyword model library of Chinese keyword “xiao-qiang-xiao-qiang” or “ni-hao-xiao-qiang” and a Chinese customized keyword library. Other keywords or performance optimizations can be provided through customized services.
Configurations
KWS configurable parameters:
- - keywords:
Keywords for wake up, and available keywords depend on KWS model. If the KWS model is a fixed keyword solution, keywords can only be chosen from the trained words. For customized solution, keywords can be customized with any combinations of same language unit(such as pinyin for Chinese). Example: “xiao-qiang-xiao-qiang”.
- - thresholds:
Threshold for wake up, range [0, 1]. The higher, less false alarm, but harder to wake up. Set to 0 to use sensitivity with predefined thresholds.
- - sensitivity:
Three levels of sensitivity are provided with predefined thresholds. The higher, easier to wake up but also more false alarm. ONLY works when thresholds set to 0.
Please refer to ${aivoice_lib_dir}/include/aivoice_kws_config.h for details.
KWS Mode
Two KWS modes are provided for different use cases. Multi mode improves KWS and ASR accuracy compared to single mode, while also increases computation consumption and heap.
KWS Mode |
Function |
Description |
|---|---|---|
single mode |
void rtk_aivoice_set_single_kws_mode(void) |
less computation consumption and less heap used |
multi mode |
void rtk_aivoice_set_multi_kws_mode(void) |
better kws and asr accuracy |
Attention
KWS mode MUST set before create instance in these flows:
aivoice_iface_full_flow_v1
aivoice_iface_afe_kws_v1
VAD (Voice Activity Detection)
Introduction
VAD is the module to detect the presence of human speech in audio.
In AIVoice, a neural network based VAD is provided and can be used in speech enhancement, ASR system etc.
Configurations
VAD configurable parameters:
- - sensitivity:
Three levels of sensitivity are provided with predefined thresholds. The higher, easier to detect speech but also more false alarm.
- - left_margin:
Time margin added to the start of speech segment, which makes the start offset earlier than raw prediction. Only affects offset_ms of VAD output, it won’t affect the event trigger time of status 1.
- - right_margin:
Time margin added to the end of speech segment, which makes the end offset later than raw prediction. Affects both offset_ms of VAD output and event time of status 0.
Please refer to ${aivoice_lib_dir}/include/aivoice_vad_config.h for details.
Note
left_margin only affects offset_ms returned by VAD, it won’t affect the VAD event trigger time. If you need get the audio during left_margin, please implement a buffer to keep audio.
ASR (Automatic Speech Recognition)
Introduction
ASR is the module to recognize speech to text.
In AIVoice, ASR supports recognition of Chinese speech command words offline.
Currently SDK provides libraries for 40 air-conditioning related command words, including “打开空调” and “关闭空调” etc. Other command words or performance optimizations can be provided through customized services.
Configurations
ASR configurable parameters:
- - sensitivity:
Three levels of sensitivity are provided with predefined internal parameters.The higher, easier to detect commands but also more false alarm.
Please refer to ${aivoice_lib_dir}/include/aivoice_asr_config.h for details.
Interfaces
Flow and Module Interfaces
Interface |
flow/module |
|---|---|
aivoice_iface_full_flow_v1 |
AFE+KWS+ASR |
aivoice_iface_afe_kws_v1 |
AFE+KWS |
aivoice_iface_afe_v1 |
AFE |
aivoice_iface_vad_v1 |
VAD |
aivoice_iface_kws_v1 |
KWS |
aivoice_iface_asr_v1 |
ASR |
All interfaces support below functions:
create()
destroy()
reset()
feed()
Please refer to ${aivoice_lib_dir}/include/aivoice_interface.h for details.
Event and Callback Message
aivoice_out_event_type |
Event Trigger Time |
Callback Message |
|---|---|---|
AIVOICE_EVOUT_VAD |
when VAD detects start or end point of a speech segment |
struct includes VAD status, offset. |
AIVOICE_EVOUT_WAKEUP |
when KWS detects keyword |
json string includes id, keyword, and score. Example: {“id”:2,”keyword”:”ni-hao-xiao-qiang”,”score”:0.9} |
AIVOICE_EVOUT_ASR_RESULT |
when ASR detects command word |
json string includes fst type, commands and id. Example: {“type”:0,”commands”:[{“rec”:”play music”,”id”:14}]} |
AIVOICE_EVOUT_AFE |
every frame when AFE got input |
struct includes AFE output data, channel number, etc. |
AIVOICE_EVOUT_ASR_REC_TIMEOUT |
when no command word detected during a given timeout duration |
NULL |
AFE Event Definition
struct aivoice_evout_afe {
int ch_num; /* channel number of output audio signal, default: 1 */
short* data; /* enhanced audio signal samples */
char* out_others_json; /* reserved for other output data, like flags, key: value */
};
VAD Event Definition
struct aivoice_evout_vad {
int status; /* 0: vad is changed from speech to silence,
indicating the end point of a speech segment
1: vad is changed from silence to speech,
indicating the start point of a speech segment */
unsigned int offset_ms; /* time offset relative to reset point. */
};
Common Configurations
AIVoice configurable parameters:
- - no_cmd_timeout:
ASR exits when no command word detected during this duration. ONLY used in full flow.
- - memory_alloc_mode:
Default mode uses SDK default heap. SRAM mode uses SDK default heap while also allocate space from SRAM for memory critical data. SRAM mode is ONLY available on RTL8713EC and RTL8726EA DSP now.
Please refer to ${aivoice_lib_dir}/include/aivoice_sdk_config.h for details.
Examples
AIVoice Full Flow Offline Example
This example shows how to use AIVoice full flow with a pre-recorded 3 channel audio and will run only once after EVB reset. Audio functions such as recording and playback are not integrated.
Steps of Using AIVoice
Select aivoice flow or modules needed. Set KWS mode to multi or single if using full flow or afe_kws flow.
/* step 1: * Select the aivoice flow you want to use. * Refer to the end of aivoice_interface.h to see which flows are supported. */ const struct rtk_aivoice_iface *aivoice = &aivoice_iface_full_flow_v1; rtk_aivoice_set_multi_kws_mode();
Build configuration.
/* step 2: * Modify the default configure if needed. * You can modify 0 or more configures of afe/vad/kws/... */ struct aivoice_config config; memset(&config, 0, sizeof(config)); /* * here we use afe_res_2mic50mm for example. * you can change these configuratons according the afe resource you used. * refer to aivoce_afe_config.h for details; * * afe_config.mic_array MUST match the afe resource you linked. */ struct afe_config afe_param = AFE_CONFIG_ASR_DEFAULT(); afe_param.mic_array = AFE_LINEAR_2MIC_50MM; // change this according to the linked afe resource. config.afe = &afe_param; /* * ONLY turn on these settings when you are sure about what you are doing. * it is recommend to use the default configure, * if you do not know the meaning of these configure parameters. */ struct vad_config vad_param = VAD_CONFIG_DEFAULT(); vad_param.left_margin = 300; // you can change the configure if needed config.vad = &vad_param; // can be NULL struct kws_config kws_param = KWS_CONFIG_DEFAULT(); config.kws = &kws_param; // can be NULL struct asr_config asr_param = ASR_CONFIG_DEFAULT(); config.asr = &asr_param; // can be NULL struct aivoice_sdk_config aivoice_param = AIVOICE_SDK_CONFIG_DEFAULT(); aivoice_param.no_cmd_timeout = 10; config.common = &aivoice_param; // can be NULL
Use
create()to create and initialize aivoice instance with given configuration./* step 3: * Create the aivoice instance. */ void *handle = aivoice->create(&config); if (!handle) { return; }
Register callback function.
/* step 4: * Register a callback function. * You may only receive some of the aivoice_out_event_type in this example, * depending on the flow you use. * */ rtk_aivoice_register_callback(handle, aivoice_callback_process, NULL);
The callback function can be modified according to user cases:
static int aivoice_callback_process(void *userdata, enum aivoice_out_event_type event_type, const void *msg, int len) { (void)userdata; struct aivoice_evout_vad *vad_out; struct aivoice_evout_afe *afe_out; switch (event_type) { case AIVOICE_EVOUT_VAD: vad_out = (struct aivoice_evout_vad *)msg; printf("[user] vad. status = %d, offset = %d\n", vad_out->status, vad_out->offset_ms); break; case AIVOICE_EVOUT_WAKEUP: printf("[user] wakeup. %.*s\n", len, (char *)msg); break; case AIVOICE_EVOUT_ASR_RESULT: printf("[user] asr. %.*s\n", len, (char *)msg); break; case AIVOICE_EVOUT_ASR_REC_TIMEOUT: printf("[user] asr timeout\n"); break; case AIVOICE_EVOUT_AFE: afe_out = (struct aivoice_evout_afe *)msg; // afe will output audio each frame. // in this example, we only print it once to make log clear static int afe_out_printed = false; if (!afe_out_printed) { afe_out_printed = true; printf("[user] afe output %d channels raw audio, others: %s\n", afe_out->ch_num, afe_out->out_others_json ? afe_out->out_others_json : "null"); } // process afe output raw audio as needed break; default: break; } return 0; }
Use
feed()to input audio data to aivoice./* when run on chips, we get online audio stream, * here we use a fix audio. * */ const char *audio = (const char *)get_test_wav(); int len = get_test_wav_len(); int audio_offset = 44; int mics_num = 2; int afe_frame_bytes = (mics_num + afe_param.ref_num) * afe_param.frame_size * sizeof(short); while (audio_offset <= len - afe_frame_bytes) { /* step 5: * Feed the audio to the aivoice instance. * */ aivoice->feed(handle, (char *)audio + audio_offset, afe_frame_bytes); audio_offset += afe_frame_bytes; }
(Optional) If need reset status, use
reset().If aivoice no longer needed, use
destroy()to destroy the instance./* step 6: * Destroy the aivoice instance */ aivoice->destroy(handle);
Please refer to ${aivoice_example_dir}/full_flow_offline for more details.
Build Example
Build Tensorflow Lite Micro Library for DSP, refer to Build Tensorflow Lite Micro Library.
Or use the prebuilt Tensorflow Lite Micro Library in {DSPSDK}/lib/aivoice/prebuilts.
Import
{DSPSDK}/example/aivoice/full_flow_offlinesource in Xtensa Xplorer.Set software configurations and modify libraries such as AFE resource, KWS resource if needed.
add include path (-I)
${workspace_loc}/../lib/aivoice/include
add library search path (-L)
${workspace_loc}/../lib/aivoice/prebuilts/$(TARGET_CONFIG) ${workspace_loc}/../lib/xa_nnlib/v1.8.1/bin/$(TARGET_CONFIG)/Release ${workspace_loc}/../lib/lib_hifi5/project/hifi5_library/bin/$(TARGET_CONFIG)/Release ${workspace_loc}/../lib/tflite_micro/project/bin/$(TARGET_CONFIG)/Release
add libraries (-l)
-laivoice -lafe_kernel -lafe_res_2mic50mm -lkernel -lvad -lkws -lasr -lfst -lcJSON -ltomlc99 -ltflite_micro -lxa_nnlib -lhifi5_dsp
Build image, please follow steps in dsp_build.
FreeRTOS
Switch to gcc project directory
cd {SDK}/amebasmart_gcc_project ./menuconfig.py
Navigate through menu path to enable Tensorflow Lite Micro Library and AIVoice
--------MENUCONFIG FOR General--------- CONFIG TrustZone ---> ... CONFIG APPLICATION ---> GUI Config ---> ... AI Config ---> [*] Enable TFLITE MICRO [*] Enable AIVoice
Select AFE Resource according to hardware, default is afe_res_2mic50mm
AI Config ---> [*] Enable TFLITE MICRO [*] Enable AIVoice Select AFE Resource ( ) afe_res_1mic ( ) afe_res_2mic30mm (X) afe_res_2mic50mm ( ) afe_res_2mic70mm
Select KWS Resource, default is fixed keyword “xiao-qiang-xiao-qiang” “ni-hao-xiao-qiang”
AI Config ---> [*] Enable TFLITE MICRO [*] Enable AIVoice Select AFE Resource Select KWS Resource (X) kws_res_xqxq ( ) kws_res_custom
Build image
./build.py -a full_flow_offline
Linux
(Optional) Modify yocto recipe
{LINUXSDK}/yocto/meta-realtek/meta-sdk/recipes-rtk/aivoice/rtk-aivoice-algo_1.2.bb.to change library such as AFE resource, KWS resource if needed.Compile the aivoice algo image using bitbake:
bitbake rtk-aivoice-algo
Glossary
- AEC
Acoustic Echo Cancellation, or echo cancellation, refers to removing the echo signal from the input signal. The echo signal is generated by a sound played through the speaker of the device then captured by the microphone.
- AFE
Audio Front End, refers to a combination of modules for preprocessing raw audio signals. It’s usually performed to improve the quality of speech signal before the voice interaction, including several speech enhancement algorithms.
- AGC
Automatic Gain Control, an algorithm that dynamically controls the gain of a signal and automatically adjust the amplitude to maintain an optimal signal strength.
- ASR
Automatic Speech Recognition, or Speech-to-Text, refers to recognition of spoken language from audio into text. It can be used to build voice-user interface to enable spoken human interaction with AI devices.
- BF
BeamForming, refers to a spatial filter designed for a microphone array to enhance the signal from a specific direction and attenuate signals from other directions.
- KWS
Keyword Spotting, or wakeup word detection, refers to identifying specific keywords from audio. It is usually the first step in a voice interaction system. The device will enter the state of waiting voice commands after detecting the keyword.
- NN
Neural Network, is a machine learning model used for various task in artificial intelligence. Neural networks rely on training data to learn and improve their accuracy.
- NS
Noise Suppression, or noise reduction, refers to suppressing ambient noises in the signal to enhance the speech signal, especially stationary noises.
- RES
Residual Echo Suppression, refers to suppressing the remained echo signal after AEC processing. It is a postfilter for AEC.
- SSL
Sound Source Localization, or direction of arrival(DOA), refers to estimating the spatial location of a sound source using a microphone array.
- TTS
Text-To-Speech, or speech synthesis, is a technology that converts text into spoken audio. It can be used in any speech-enabled application that requires converting text to speech imitating human voice.
- VAD
Voice Activity Detection, or speech activity detection, is a binary classifier to detect the presence or absence of human speech. It is widely used in speech enhancement, ASR system etc, and can also be used to deactivate some processes during non-speech section of an audio session, saving on computation or bandwidth.